








































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)






















































































































































































Subject-Driven Image Evaluation Gets Simpler: Google Researchers Introduce REFVNLI to Jointly Score Textual Alignment and Subject Consistency Without Costly APIs
Text-to-image (T2I) generation has evolved to include subject-driven approaches, which enhance standard T2I models by incorporating reference images alongside text prompts. This advancement allows for more precise subject representation in generated images. Despite the promising applications, subject-driven T2I generation faces a significant challenge of lacking reliable automatic evaluation methods. Current metrics focus either on text-prompt […] The post Subject-Driven Image Evaluation Gets Simpler: Google Researchers Introduce REFVNLI to Jointly Score Textual Alignment and Subject Consistency Without Costly APIs appeared first on MarkTechPost.

Text-to-image (T2I) generation has evolved to include subject-driven approaches, which enhance standard T2I models by incorporating reference images alongside text prompts. This advancement allows for more precise subject representation in generated images. Despite the promising applications, subject-driven T2I generation faces a significant challenge of lacking reliable automatic evaluation methods. Current metrics focus either on text-prompt alignment or subject consistency, when both are essential for effective subject-driven generation. While more correlative evaluation methods exist, they rely on costly API calls to models like GPT-4, limiting their practicality for extensive research applications.
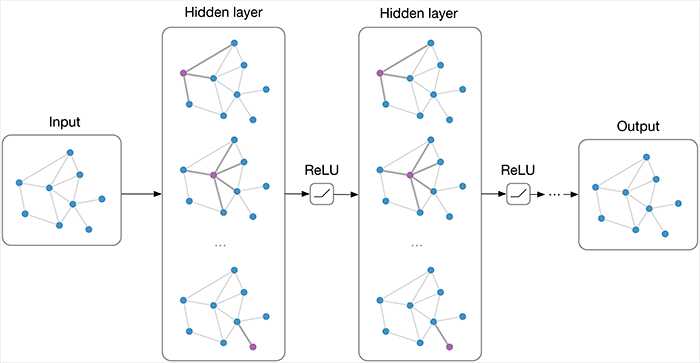
Evaluation approaches for Visual Language Models (VLMs) include various frameworks, with text-to-image (T2I) assessments focusing on image quality, diversity, and text alignment. Researchers utilize embedding-based metrics like CLIP and DINO for subject-driven generation evaluation to measure subject preservation. Complex metrics such as VIEScore and DreamBench++ utilize GPT-4o to evaluate textual alignment and subject consistency, but at a higher computational cost. Subject-driven T2I methods have developed along two main paths: fine-tuning general models into specialized versions capturing specific subjects and styles, or enabling broader applicability through one-shot examples. These one-shot approaches include adapter-based and adapter-free techniques.
Researchers from Google Research and Ben Gurion University have proposed REFVNLI, a cost-efficient metric that simultaneously evaluates textual alignment and subject preservation in subject-driven T2I generation. It predicts two scores, textual alignment and subject consistency, in a single classification based on a triplet For training REFVNLI, a large-scale dataset of triplets For subject consistency, REFVNLI ranks among the top two metrics across all categories and performs best in the Object category, exceeding the GPT4o-based DreamBench++ by 6.3 points. On ImagenHub, REFVNLI achieves top-two rankings for textual alignment in the Animals category and the highest score for Objects, outperforming the best non-finetuned model by 4 points. It also performs well in Multi-subject settings, ranking in the top three. REFVNLI achieves the highest textual alignment score on KITTEN, but has limitations in subject consistency due to its identity-sensitive training that penalizes even minor mismatches in identity-defining traits. Ablation studies reveal that joint training provides complementary benefits, with single-task training resulting in performance drops.
In this paper, researchers introduced REFVNLI, a reliable, cost-effective metric for subject-driven T2I generation that addresses both textual alignment and subject preservation challenges. Trained on an extensive auto-generated dataset, REFVNLI effectively balances robustness to identity-agnostic variations such as pose, lighting, and background with sensitivity to identity-specific traits, including facial features, object shape, and unique details. Future research directions include enhancing REFVNLI’s evaluation capabilities across artistic styles, handling textual modifications that explicitly alter identity-defining attributes, and improving the processing of multiple reference images for single and distinct subjects.
Check out the Paper. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 90k+ ML SubReddit.





