![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)


















































































































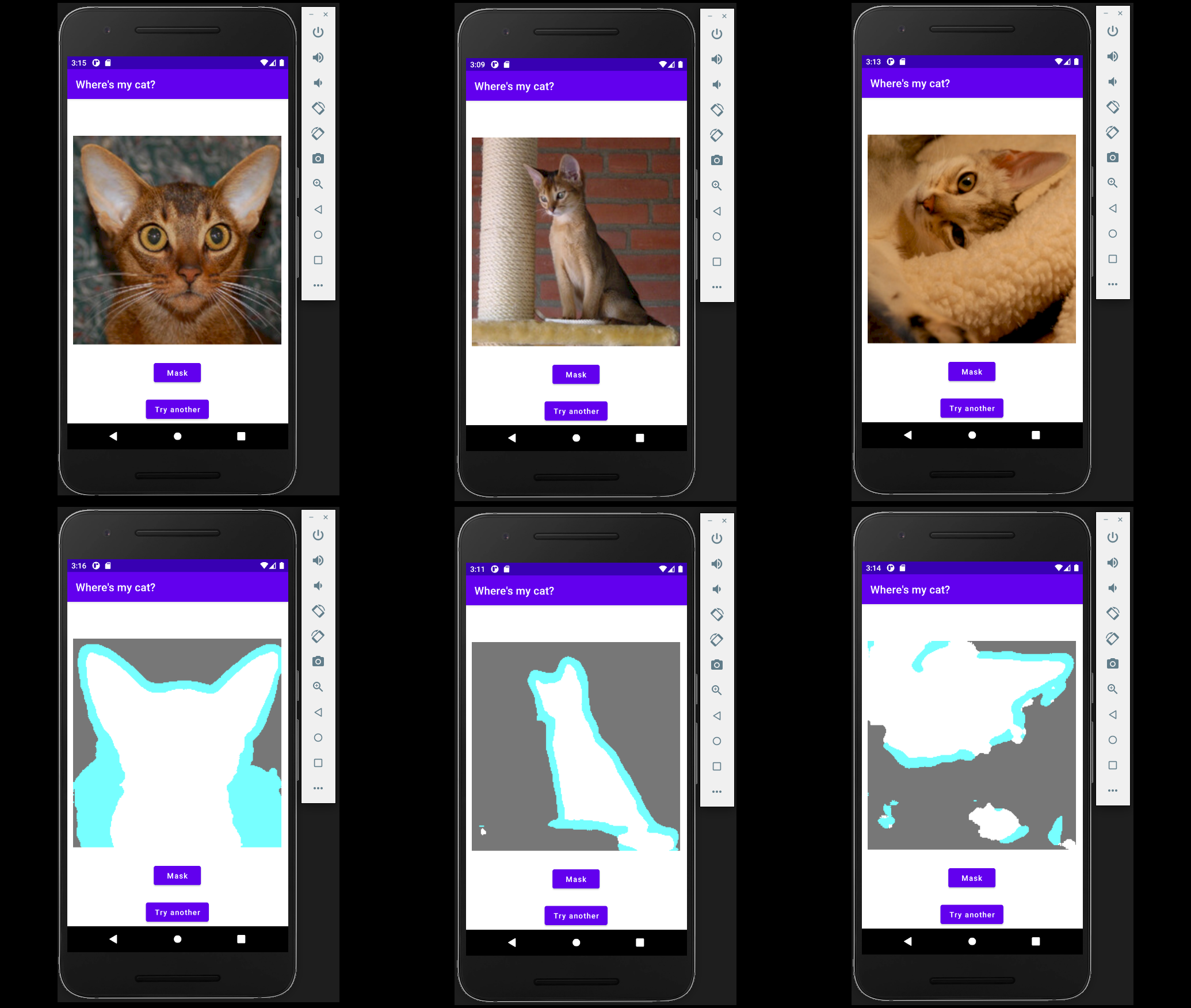




































































Vision Language models: towards multi-modal deep learning
A review of state of the art vision-language models such as CLIP, DALLE, ALIGN and SimVL
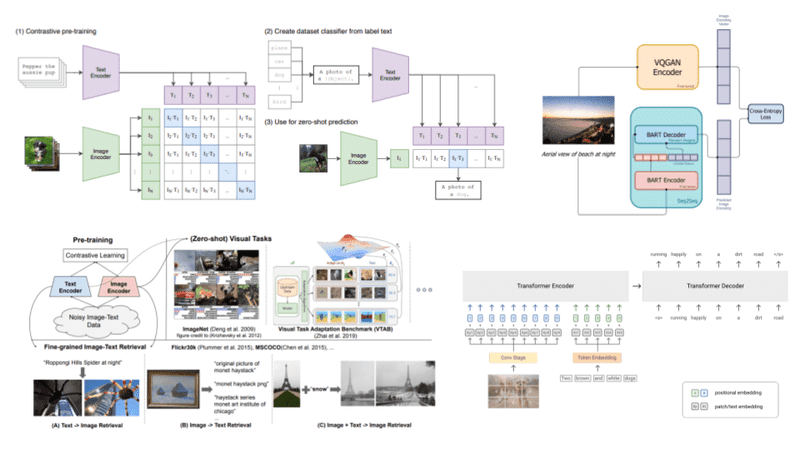
A review of state of the art vision-language models such as CLIP, DALLE, ALIGN and SimVL